HIGHLIGHTS
An end-to-end pipeline that turns scattered, unstructured job postings into one structured, searchable board.
Solo Developer — System Design, AI Pipeline, Backend, Frontend, Infrastructure
Python (Telethon) · Gemini 2.0 Flash
RabbitMQ · Express 5 · PostgreSQL
Next.js 16 — three services in production
~2 months to v1, live at fetchjobs.in
100% uptime — public status page
Every day, hundreds of developer job postings move through Indian Telegram channels — unstructured text in every imaginable format, scattered across channels, buried between memes and announcements. If you wanted these jobs, your only option was reading every channel, every day.
I designed and built the entire system end to end: a Python listener that watches the channels in real time, an AI parsing pipeline that turns raw messages into structured data, a message queue that guarantees nothing gets lost, and the API and web app that serve it — all running in production on a ~$26/month budget.
FetchJobs has parsed 738 jobs into structured, searchable cards so far, at roughly 95% field accuracy — and the pipeline is still running on its own, months after the last commit.

LinkedIn, Naukri, and Internshala never see these postings. A huge share of early-career developer roles in India are shared informally — a recruiter drops three lines of text into a Telegram channel and moves on.
The message might be plain text, or emoji-formatted, or have the apply link hidden inside an inline keyboard button. There was no structure, no deduplication, no way to search.
Manually monitoring channels and hoping you scroll past the right message in time. For something as important as a first job, that’s a terrible system — and nobody had built the pipeline to fix it.
No two messages look alike. Plain text, bold-and-emoji formatting, links in text, links in buttons, links in web previews — a rule-based parser would need hundreds of patterns and still miss.
The AI budget was zero. Gemini’s free tier allows 15 requests per minute — every message must respect a hard global rate limit or parsing stops entirely.
The infra budget was ~$26/month. Two Azure B1 instances, free-tier Postgres, free-tier RabbitMQ. Every architectural choice had a price ceiling.
Solo, in two months. Every component — scraper, parser, queue, API, auth, payments, frontend — one person, alongside college.
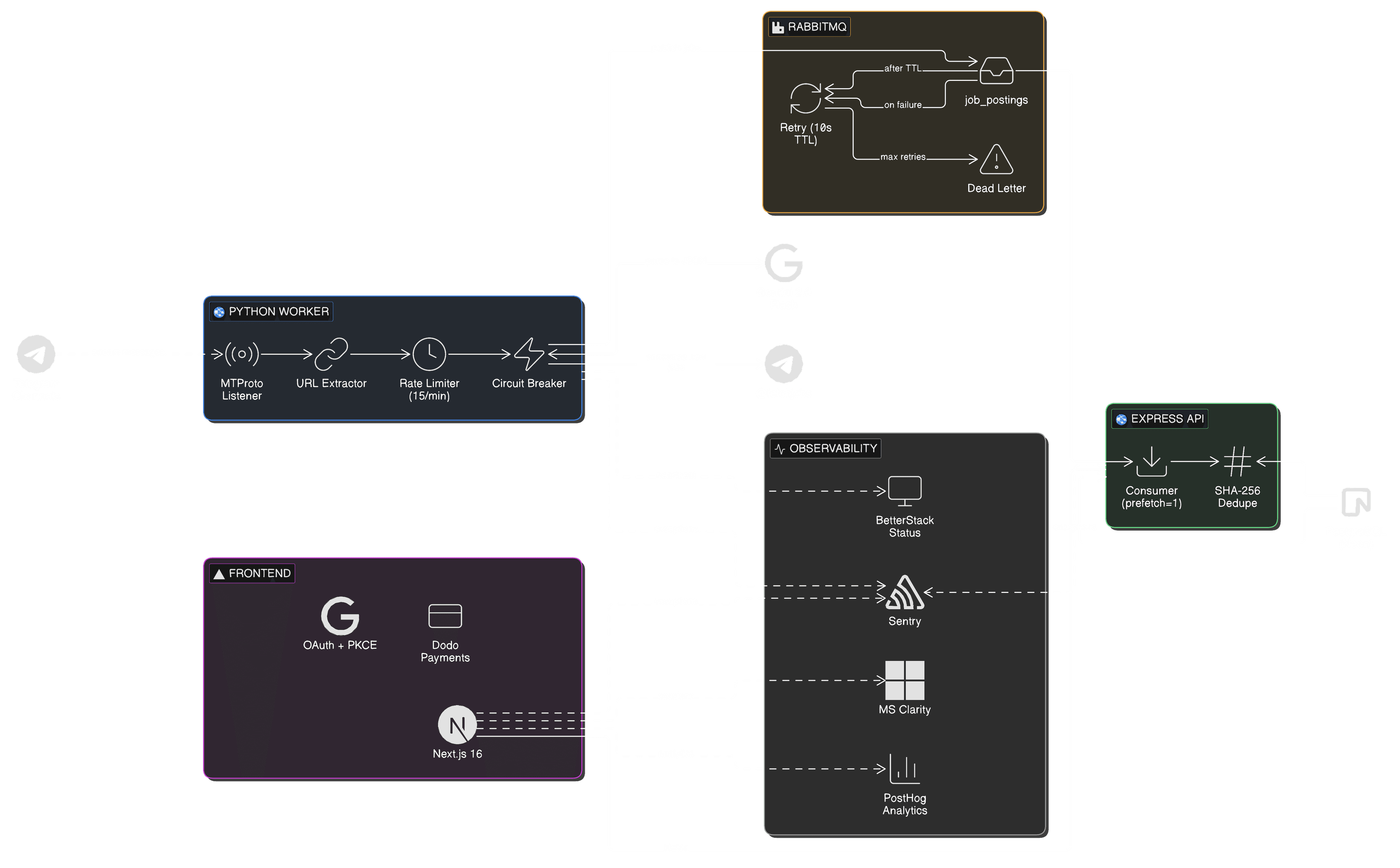
A Telethon client subscribes to the channels over MTProto. When a message lands, the listener extracts URLs from four different places Telegram can hide them — text entities, inline keyboard buttons, web previews, and embedded webpage media — and appends them to the raw text.
That enhanced text goes to Gemini 2.0 Flash with a structured-output prompt, which returns a fixed schema: role, company, location, salary range, experience, batch eligibility, apply link — and an is_job confidence gate that filters out the memes and announcements.
The first prompt produced apply links full of tracking parameters, misclassified channel announcements as jobs, and dropped fields. The fix wasn’t more code — it was treating the prompt like a system under test.
Three iterations later: explicit URL-cleaning rules, an 80% confidence threshold on is_job, and field-by-field null instructions. Manually verifying 100 parsed jobs put accuracy at roughly 70% before, 95% after.
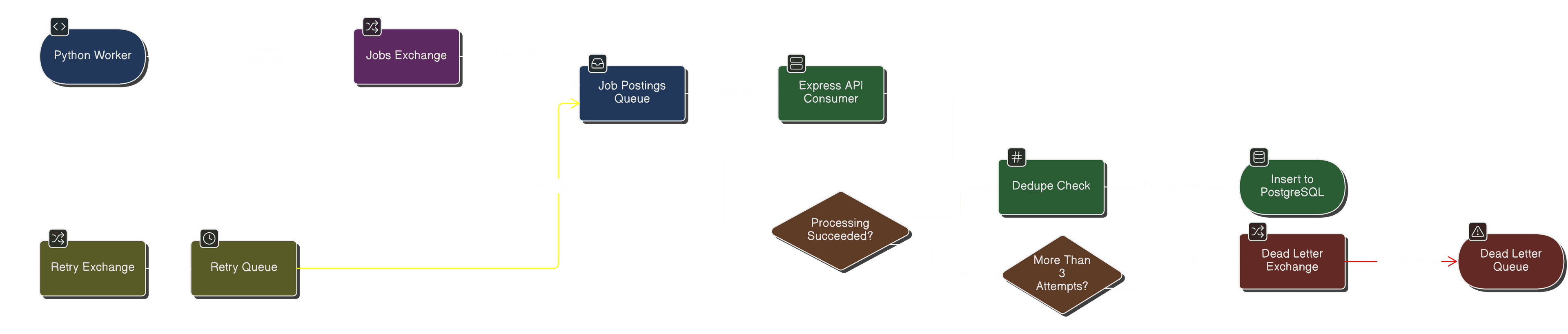
The obvious design was an HTTP POST from the scraper to the API. But if the API is mid-deploy, the job is gone — and retry logic would need building twice.
Instead, RabbitMQ sits between them with a three-tier topology: the main queue, a retry queue with a 10-second TTL that dead-letters back (up to 3 attempts), and a permanent dead-letter queue for manual review. If the API restarts during a deploy, jobs simply wait.
Gemini goes down, gets slow, or rate-limits — so the parser wraps it in a circuit breaker: five failures open the circuit, sixty seconds later a half-open probe tests recovery. A deque-based sliding window keeps requests under the 15 RPM ceiling with exact sleep timing instead of busy-waiting.
Even Azure itself needed defending against: App Service sends a SIGTERM during startup as a health probe. The worker counts signals — first one ignored, second one triggers an ordered graceful shutdown.
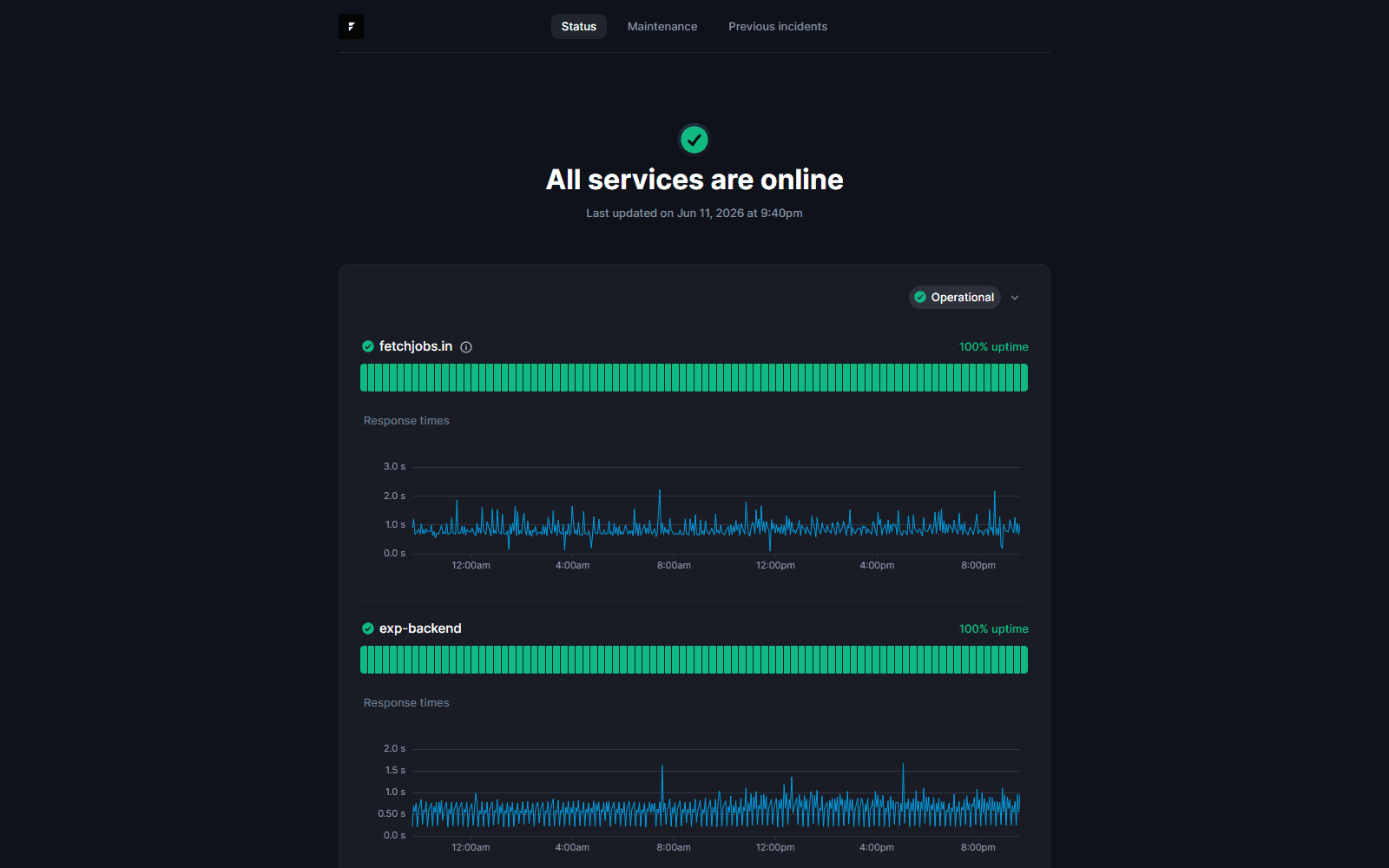
The receipts are public: status.fetchjobs.in tracks all three services live — 100% uptime across the board.
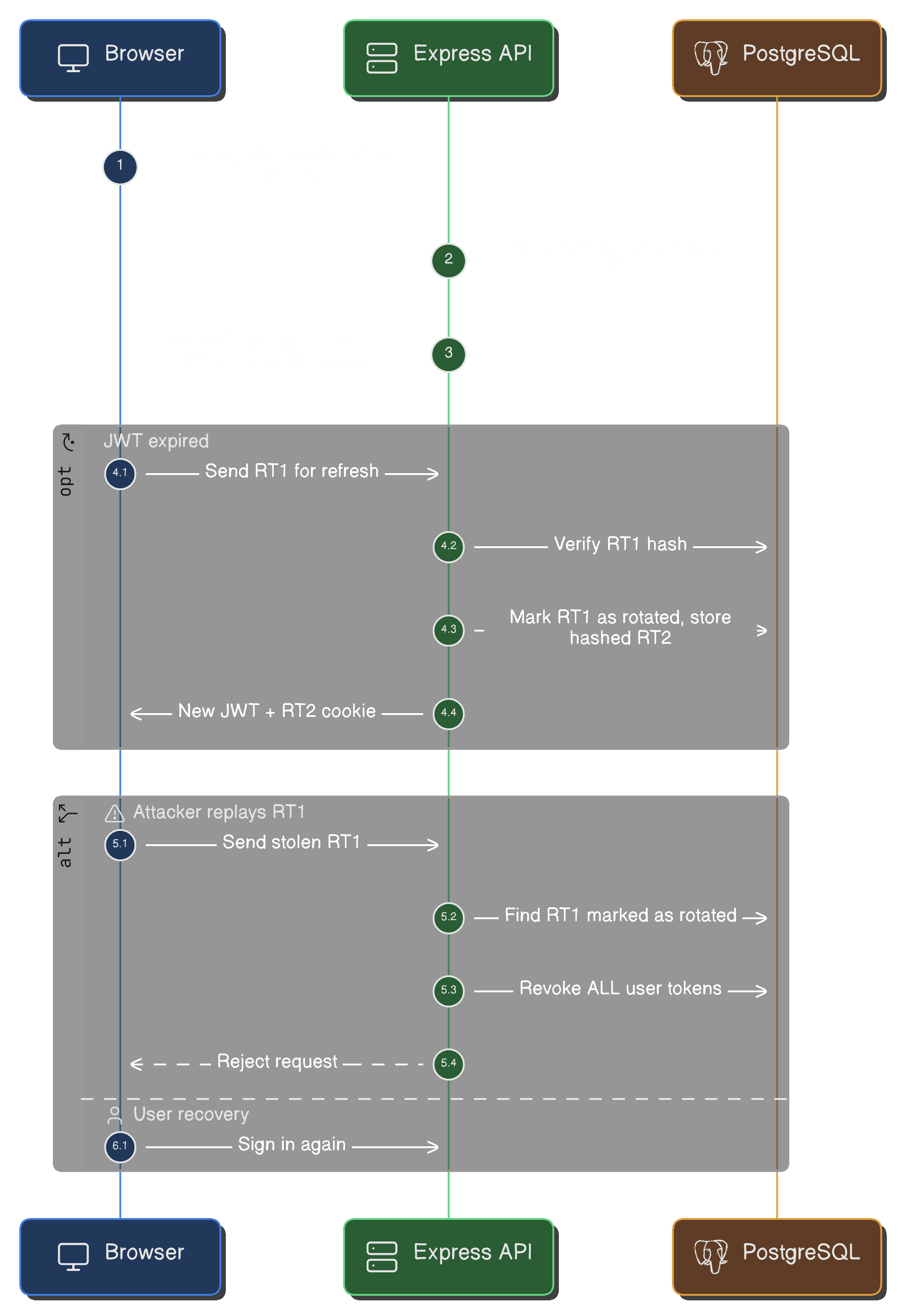
After switching to Neon’s serverless HTTP driver, every OAuth login silently failed — users bounced back to the login page with no error anywhere.
The root cause took the longest of any bug in the project: the driver serializes timestamps as ISO strings, and the ORM’s timestamp mapping silently returned null for every timestamp in the system. Sessions never expired. State cleanup never ran. Every feature touching time was quietly broken.
For a project with real users and real payments, “good enough” auth wasn’t. The final design: Google OAuth with PKCE, short-lived JWTs in httpOnly cookies, and rotating refresh tokens stored only as bcrypt hashes.
CSRF is handled with double-submit cookies on every mutation, and rate limiting backs the auth endpoints.